
MOOC Estimation des incertitudes de mesure en analyse chimique
11. Approche par validation dite de laboratoire unique
11.1. Principes
https://sisu.ut.ee/measurement/101-principle-absolute-and-relative-quantities
Dans l’approche Nordtest, l’incertitude est considérée comme due à deux composantes :
- La composante de reproductibilité intra-laboratoire (précision intermédiaire). Cette composante d’incertitude prend en compte toutes les sources d’incertitude aléatoires à long terme (c’est-à-dire plusieurs mois, de préférence un an). Ainsi, certaines sources d’incertitude qui sont systématiques en une journée deviendront aléatoires à long terme.
- La composante de biais. Cette composante prend en compte les effets systématiques qui provoquent un biais à long terme (mais pas ceux qui provoquent simplement un biais au cours d’une journée donnée). Le biais à long terme peut être considéré comme la somme du biais de la procédure (biais inhérent à la nature de la procédure) et du biais de laboratoire (biais causé par la façon dont la procédure est mise en œuvre en laboratoire).
Introduction à l'estimation de l'incertitude basée sur des données de validation et de contrôle qualité (l'approche Nordtest)
http://www.uttv.ee/naita?id=17909
| Let us now look at the uncertainty estimation approach which is based on validation and quality control data. And it is also quite often called the Nordtest approche and i've been using also this name throughout this course. So in this approach all the effects that contribute to the uncertainty are divided into random effects and systematic effects, and those random and systematic effects are then quantified separately. And in very broad terms and in a simplified way we could say that the main equation of this approach looks like this. The combined standard uncertainty of the result is found by combining the overall uncertainty arising from random effects and the overall uncertainty arising from the possible systematic effects. I will explain later on why this "possible" is put here and why it is in italic. It is now also very important to mention that both these random and systematic effects, they are taken or they are meant to be found at long-term level. Meaning the effects that are random are random during the time period of several months, and the same goes about the systematic effects. So the time frame that we are looking here is several months at least preferably year. | Regardons maintenant l'approche de l'estimation de l'incertitude qui est basée sur des données de validation et de contrôle de la qualité. Et cette approche est souvent appelée l'approche Nordtest et j'ai aussi utilisé ce nom tout au long de ce cours. Donc dans cette approche, tous les effets qui contribuent à l'incertitude sont partagés entre effets aléatoires et effets systématiques, et ces effets aléatoires et systématiques sont ensuite quantifiés séparément. Et dans des termes très généraux et dans une manière très simplifée nous pourrions dire que l'équation mathématique de cette approche ressemble à cela. L'incertitude-type composée de ce résultat est trouvée en combinant l'incertitude totale provenant des effets aléatoires et l'incertitude totale provenant des effets systématiques possibles. Je vais expliquer plus tard pourquoi ce "possible" est mis ici et pourquoi il est en italique. Il est maintenant également très important de mentionner que ces deux effets, aléatoires et systématiques, sont pris ou censés être trouvés sur le long terme. Cela signifie que les effets qui sont aléatoires sont aléatoires pendant une période de temps de plusieurs mois, et c'est la même chose pour les effets systématiques. Donc la période que nous regardons ici est au moins plusieurs mois, de préférence une année. |
L’équation principale de l’approche Nordtest est :
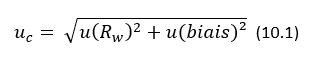
Ici u (Rw) représente la composante de reproductibilité intra-laboratoire de l'incertitude et u (biais) représente la composante d'incertitude en tenant compte des biais possibles. L'incertitude de mesure résultante uc n'est pas directement liée à un résultat spécifique, car elle est calculée à l'aide des données des mesures précédentes. On peut donc dire que l'incertitude obtenue avec l'approche Nordtest caractérise la procédure d'analyse plutôt qu'un résultat concret. Si l'incertitude d'un résultat concret est nécessaire, elle est affectée au résultat.
Pour cette raison, il est nécessaire de décider s'il faut exprimer l'incertitude en termes absolus (c'est-à-dire en unités de la quantité mesurée) ou en termes relatifs (c'est-à-dire en tant que rapport d'incertitude à la valeur de la quantité mesurée ou en pourcentage de la valeur mesurée). Les règles de bases :
- À de faibles concentrations (près de la limite de détection, niveau de trace), utiliser des incertitudes absolues
L'incertitude ne dépend pas beaucoup du niveau d'analyte
- À des concentrations moyennes et supérieures, utiliser des incertitudes relatives
L'incertitude est à peu près proportionnelle au niveau d'analyte
- En général : utilisez ce qui est le plus constant avec une concentration changeante
L'équation principale de l'approche Nordtest. Quantités absolues et relatives
http://www.uttv.ee/naita?id=17911
| The equation on the previous slide can be rewritten as you can see here on this line and this equation now comes directly from the Nordtest guide and also we are using throughout this explanation the terminology and the symbols that are used directly in the Nordtest guide. So the "uRw" component takes into account the long term random effects and it is actually the same thing as within lab long term reproducibility which we have seen already in a previous lecture. And secondly the "u(bias)" takes into account the possible systemic effects in long term and it is also interesting and important to note that this equation now can be used both with absolute and with relative values. And whether we use absolute values or whether we use relative value we have to determine based on the concrete situation. And this situation arises from the fact that the standard uncertainty that we find according to this approach is by itself not linked to any particular measurement result, in fact, we assign it to a result that we want to present to our customer. Whether we use absolute or relative quantities, depends on several things, but let me give you a rule of Thumb which one to use. And the rule of Thumb goes as follows, if your concentrations, if the contents of the analyte in the sample are very low, so you are working near the detection or near the quantification limit, then uncertainty is not very much dependent on the analyte level and then absolute quantities are more appropriate. If however you work at medium concentrations or at high concentrations then the uncertainty in chemical analysis very often is roughly proportional to the analyte level. This proportionality usually is not strict, so if you look at the uncertainties at different concentration levels then they differ slightly, but nevertheless the relative uncertainty stays more or less constant while the absolute uncertainty increases with the increasing concentration. And the general rule here would be whichever is more constant is better to use, meaning if we change in concentration, the absolute uncertainty remains constant then you should use absolute uncertainties. If we change in concentration, the relative uncertainty remains constant then you should use the relative uncertainty. | L'équation sur la diapositive précédente peut être réécrite comme vous pouvez le voir ici sur cette ligne. Cette équation provient directement du guide Nordtest et aussi nous utilisons tout au long de l'explication la terminologie et les symboles qui sont utilisés directement dans le guide Nordtest. Donc l'élément "u(Rw)" prend en compte les effets aléatoires de longue durée et c'est en fait la même chose que la reproductibilité intra-laboratoire à long terme que nous avons déjà vu dans la séance précédente. Et deuxièmement le "u(biais)" prend en compte les effets systématiques possibles à long terme et c'est aussi intéressant et important de noter que cette équation maintenant peut être utilisée aussi bien avec des valeurs absolues et relatives. Et que nous utilisons des valeurs absolues ou des valeurs relatives, nous devons le déterminer en fonction du contexte concret. Et cette situation résulte du fait que l'incertitude type que nous trouvons d'après cette approche est en elle-même non liée à un résultat de mesure particulier, en effet, nous l'attribuons à un résultat que nous voulons présenter à notre client. Le fait d'utiliser des quantités absolues ou relatives, dépend de plusieurs choses, mais laissez-moi vous donner une règle de Thumb que nous devons utiliser. La règle de Thumb est la suivante, si vos concentrations, si les teneurs en analyte dans l'échantillon sont très faibles, donc vous travaillez proche de la limite de détection ou de quantification, alors l'incertitude ne dépend pas beaucoup de la teneur en analyte et donc les quantités absolues sont plus appropriées. Si par contre vous travaillez à des concentrations moyennes ou à des hautes concentrations alors l'incertitude dans les analyses chimiques est très souvent à peu près proportionnelle au niveau d'analyte. Cette proportionnalité n'est habituellement pas stricte, donc si vous regardez les incertitudes aux différents niveaux de concentration alors ils diffèrent légèrement, mais néanmoins l'incertitude relative reste plus ou moins constante pendant que l'incertitude absolue croît avec l'augmentation de la concentration. Et la règle générale ici serait qu'il est préférable d'utiliser celle qui est la plus constante. Ce qui signifie que si nous changeons en concentration et l'incertitude absolue reste constante alors vous devriez utiliser les incertitudes absolues. Si nous changeons en concentration et l'incertitude relative reste constante alors vous devriez utiliser l'incertitude relative. |
Aperçu de la mise en œuvre pratique de l'approche Nordtest
http://www.uttv.ee/naita?id=17912
| Let us look now how to implement this approach in practice and this slide here presents the steps of uncertainty estimation using the Nordtest approach. Some of the steps are the same as they were in the modeling approach but some are different so as it was with the modeling approach we start by specifying the measurement but then here we don't have the model part it doesn't mean that we don't need any model we do need the model because we need to calculate the results somehow when this goes via the measurement model however the model is not directly a part of the uncertainty estimation approach as such so in the second and third step we quantify separately the "urw" component or the so-called, component taking into account the random effects and the component taking into account the possible bias and then both components need to be converted to the standard uncertainties and the remaining quadratic curves exactly as it was in the modeling approach. We can calculate from thesecomponents the combined standard uncertainty and finally we calculate the expanded answer. | Regardons maintenant comment mettre en oeuvre cette approche dans la pratique et cette diapositive ici présente les étapes de l'estimation de l'incertitude en utilisant l'approche Nordtest. Certaines de ces étapes sont les mêmes que celles de l'approche par modélisation mais certaines sont différentes de celles de l'approche par modélisation. Nous commençons par spécifier la mesure mais après ici nous n'avons pas la partie modélisée, cela ne veut pas dire que nous n'avons pas besoin d'un modèle, nous en avons besoin car nous devons calculer les résultats d'une certaine façon quand cela va via le modèle de mesure. Par contre le modèle ne fait pas directement partie de l'approche de l'estimation de l'incertitude en tant que tel. Donc dans les deuxième et troisième étapes nous quantifions séparément l'élément "u(Rw)" ou aussi appelé l'élément qui prend en compte les effets aléatoires, et l'élément prenant en compte les biais possibles. Et ensuite les deux éléments doivent être convertis en incertitudes-types et des courbes quadratiques restantes exactement comme c'était dans l'approche par modélisation. Nous pouvons calculer à partir de ces éléments l'incertitude-type composée et finalement nous calculons la réponse étendue. |
Les principales étapes du processus d'évaluation de l'incertitude de mesure avec l'approche Nordtest :
- Spécifier le mesurande
- Quantifier la composante Rw u(Rw)
- Quantifier la composante de biais u(biais)
- Convertir les composants en incertitudes-types u(x)
- Calcul de l'incertitude-type composée uc
- Calcul de l'incertitude élargie U
***
[1] Un exemple typique est le titrage si un nouveau titrant est préparé chaque semaine. Dans une semaine donnée, la concentration de titrant est un effet systématique, mais à long terme, elle devient aléatoire, car de nombreux lots de titrant seront impliqués. Un exemple similaire typique est le graphique d'étalonnage s'il est préparé quotidiennement : chaque jour, le biais possible d'étalonnage est un effet systématique, mais à long terme, il devient aléatoire.