
MOOC Estimation des incertitudes de mesure en analyse chimique
4. Les concepts et outils fondamentaux
4.6. La distribution de Student
https://sisu.ut.ee/measurement/35-other-distribution-functions-student-distribution
Résumé : Comme les valeurs individuelles, la valeur moyenne calculée à partir de celles-ci est également une quantité aléatoire. Si les valeurs individuelles sont réparties selon la loi de distribution normale, la valeur moyenne calculée à partir de celles-ci est répartie selon la distribution de Student (également appelée distribution t). Les propriétés de la distribution t comparées à la distribution normale sont expliquées. Il est important de noter que la forme de la courbe de distribution t dépend du nombre de degrés de liberté. Si le nombre de valeurs individuelles approche l'infini, la forme de la courbe de distribution t se rapproche de la courbe de distribution normale.
La distribution de Student
http://www.uttv.ee/naita?id=17708
| Let us now examine one more distribution function : the T or so-called Student distribution. Student distribution is somewhat similar to the normal distribution in that it is also characterized by a mean value and the standard deviation. But in addition to these two, it is also characterized by the number of degrees of freedom, which makes it different from the normal distribution function. When do we encounter Student distribution ? The Student distribution is encountered first of all in all those cases where we use mean values, so whenever we carry out repeated measurements of the same quantity and we use the mean value of those repetitions. The mean value also is a random quantity and also obeys a distribution function. and the mean value of normally distributed values is distributed according to the Student distribution. And let us go for a moment back to the normal distribution. We have examined that quite carefully and we have discovered that these probabilities here are quite important because they set for us the coverage probabilities of the different uncertainties. So for example, standard uncertainty has the coverage probability of roughly 68% and k2 expanded uncertainty has the coverage probability of roughly 95% if the result is distributed according to the normal distribution. When I explained that, I already mentioned that there will be cases where this 95 percent will not hold if we use k2 expanded uncertainty. In actually one of the main reasons, that it does not always hold, is the Student distribution. And let us see how it is done and let us see what the number of the degrees of freedom means. So the number of degrees of freedom is equal to the number of parallel measurements minus one. So if the mean value is obtained from 101 measurements, then the number of degrees of freedom is 100. If from 11 measurements it's 10, if from 6 measurements it's 5 and if it is obtained from 3 measurements only, then the number of degrees of freedom is 2. Now the Student distribution has an interesting property that whenever the number of degrees of freedom approaches infinity, the Student distribution approaches the normal distribution. And for all practical cases, we can see that, let's say from 50 to 30 measurements, give us distribution function which is almost indistinguishable from the normal distribution. Therefore, the normal distribution curve here, which corresponds to 100 degrees of freedom, can be regarded as the normal distribution. Therefore, the student distribution curve here, which is obtained from 101 measurements, can be regarded as a normal distribution. But now, as the number of degrees of freedom decreases, which is the consequence of lower number of repeated measurements, lower number of parallel measurements, the shape of the distribution function changes and the shape changes interestingly. So you see here, in the center, the intensity decreases so that the probability of the true mean value being here decreases somewhat, but at the same time, the tails, the tails become higher and higher more powerful. Therefore, we can say that the probability to some extent is flowing away from the middle into the tails and this is what causes, that if our result is distributed according to the normal distribution, then k2 uncertainty can be uncertainty with much less probability than 95%. And we can look at it, this way, if it is the normal distribution, then the area of this part here plus the area of this part here is roughly 4.5%, which is the probability that remains outside of this 95.5%. But we see that, as the number of degrees of freedom decreases, the tail gets more and more and more intense, meaning the area here gets larger and larger. Therefore, whenever we have lower number of degrees of freedom, the probability that we can achieve by the k2 expanded uncertainty becomes lower than 95%. It can be 93, 92 even 85% if the number of degrees of freedom is small. Now, interestingly, as we will also see and comment on in some of the examples, usually our measurements results are distributed neither normally nor according to the Student distribution. Their distribution usually is the convolution of different distributions. And as I have been explaining already, whenever our measurement result is influenced by many different input quantities, then if each of those input quantities has their own distribution function, then if the number of those quantities or influencing factors approaches infinity, then the distribution function approaches the normal distribution, so that if the measurement result is influenced by many many factors then usually we can assume that it is distributed normally. In reality however, very often it happens that there is one, two or three strong influencing factors and the remaining ones are not so strong. And in such a case, the strong factors determine the shape of the distribution function of the output quantity. And if one of those strong influencing factors has T distribution with low number of degrees of freedom, then our result will be distributed according to a convolution of normal and T distribution and in such a case, the k2 uncertainty corresponds to coverage probability which is less than 95%. In practice, such situation most often occurs if there is an important and influential input quantity which is obtained as mean value of, let's say, three, four or five measurements. So if three, four or five measurements are averaged into a mean value, and this mean value has an important influence on the measurement uncertainty, then we can be quite sure that the result is distributed not according to purely normal distribution but by a mixed distribution and convolution of the normal and Student distribution. |
Examinons maintenant une autre fonction de distribution : la T ou la dite distribution de Student. La distribution de Student est assez similaire à la distribution normale dans le sens où elle est aussi caractérisée par une valeur moyenne et un écart-type. Mais en plus de ces deux valeurs, elle est aussi caractérisée par le nombre de degrés de liberté, ce qui la rend différente de la fonction de distribution normale. Quand rencontrons-nous la distribution de Student ? La distribution de Student est rencontrée tout d'abord dans tous les cas où nous utilisons des valeurs moyennes, donc lorsque nous effectuons des mesures répétées de la même quantité et que nous utilisons la valeur moyenne de ces répétitions. La valeur moyenne est également une quantité aléatoire et obéit aussi à une fonction de distribution. La valeur moyenne des valeurs distribuées normalement est distribuée selon la distribution de Student. Revenons un instant à la distribution normale. Nous avons examiné cela très attentivement et nous avons découvert que ces probabilités ici sont plutôt importantes car elles nous posent les probabilités de couverture des différentes incertitudes. Ainsi, par exemple, l'incertitude type a une probabilité de couverture d'environ 68% et l'incertitude élargie k2 a une probabilité de couverture d'environ 95% si le résultat est distribué selon la distribution normale. Lorsque j'ai expliqué cela, j'ai déjà mentionné qu'il y aurait des cas où ces 95% ne tiendront pas si nous utilisons l'incertitude élargie k2. En fait, l'une des raisons principales, qui ne tient pas toujours, est la distribution de Student. Voyons comment cela se fait et que signifie le nombre de degrés de liberté. Le nombre de degrés de liberté est égal au nombre de mesures parallèles moins un. Donc si la valeur moyenne est obtenue à partir de 101 mesures, alors le nombre de degrés de liberté est 100. À partir de 11 mesures c'est 10, à partir de 6 mesures c'est 5 et si elle est obtenue à partir de 3 mesures seulement, alors le nombre de degrés de liberté est 2. Maintenant, la distribution de Student possède une propriété intéressante qui est qu'à chaque fois que le nombre de degrés de liberté approche l'infini, la distribution de Student approche la distribution normale. Pour tous les cas pratiques, nous pouvons voir que, disons pour 50 à 30 mesures, cela nous donne une fonction de distribution qui est presque non distinguable de la distribution normale. Par conséquent, la courbe de distribution normale ici, qui correspond à 100 degrés de liberté, peut être considérée comme une distribution normale. Par conséquent, la courbe de distribution de Student ici, qui est obtenue à partir de 101 mesures, peut être considérée comme une distribution normale. Mais maintenant, comme le nombre de degrés de liberté décroit, ce qui est la conséquence d'un nombre inférieur de mesures répétées, d'un nombre inférieur de mesures parallèles, la forme de la fonction de distribution change et elle change de façon intéressante. Vous pouvez donc voir ici, au centre, que l'intensité diminue de sorte que la probabilité de la valeur moyenne vraie ici décroit quelque peu, mais dans un même temps, les queues deviennent de plus en plus puissantes. C'est pourquoi, nous pouvons dire que la probabilité, dans une certaine mesure, s'éloigne depuis le centre vers les queues et cela implique, que si notre résultat est distribué selon la distribution normale, alors l'incertitude k2 peut être une incertitude avec une probabilité bien inférieure à 95%. Nous pouvons l'examiner de cette manière : si c'est une distribution normale, alors l'aire de cette partie ici plus l'aire de cette partie là est d'environ 4,5%, ce qui est la probabilité qui reste en dehors de 95,5%. Mais nous voyons que, comme le nombre de degrés de liberté décroit, la queue devient de plus en plus intense, ce qui signifie que l'aire devient de plus en plus large. De fait, chaque fois que nous avons un nombre de degré de liberté plus faible, la probabilité que nous pouvons atteindre avec l'incertitude élargie k2 devient inférieure à 95%. Ça peut être 93, 92, même 85% si le nombre de degré de liberté est petit. Maintenant, il est intéressant de noter que, comme nous le verrons et commenterons dans certains exemples, nos résultats de mesures ne sont généralement pas distribués normalement ni selon la distribution de Student. Leur distribution est généralement la convolution de différentes distributions. Comme je l'ai déjà expliqué, lorsque notre résultat de mesure est influencé par de nombreuses quantités d'entrée différentes, si chacune de ces quantités d'entrée a sa propre fonction de distribution, si le nombre de ces quantités ou de facteurs d'influence approche l'infini, alors la fonction de distribution approche la distribution normale, de sorte que si le résultat de mesure est influencé par de nombreux facteurs, alors nous pouvons généralement supposer qu'il est distribué normalement. En réalité cependant, il arrive très souvent qu'il y ait un, deux ou trois facteurs d'influence forts et que les autres ne le soient pas autant. Dans ce cas, les facteurs forts déterminent la forme de la fonction de distribution de la quantité de sortie. Et si un de ces facteurs d'influence forts a une distribution T avec un faible nombre de degrés de liberté, alors notre résultat sera distribué selon une convolution de distribution normale et T et dans un tel cas, l'incertitude k2 correspond à une probabilité de couverture qui est inférieure à 95%. En pratique, une telle situation se produit le plus souvent s'il y a une quantité importante et influente d'entrée qui est obtenue en tant que valeur moyenne de, disons trois, quatre ou cinq mesures. Donc si trois, quatre ou cinq mesures sont moyennées en une valeur moyenne, et que cette valeur moyenne a une influence importante sur l'incertitude de mesure, alors nous pouvons être assez sûrs que le résultat est distribué non pas selon une distribution purement normale mais par une distribution et convolution mixte d'une distribution normale et une distribution de Student. |
Si une mesure est répétée et que la moyenne est calculée à partir des résultats des mesures individuelles, alors, tout comme les résultats individuels, leur moyenne sera également une quantité aléatoire. Si les résultats individuels sont normalement distribués, leur moyenne est répartie selon la distribution de Student (également appelée distribution t). La distribution de Student est présentée dans le schéma 3.5.
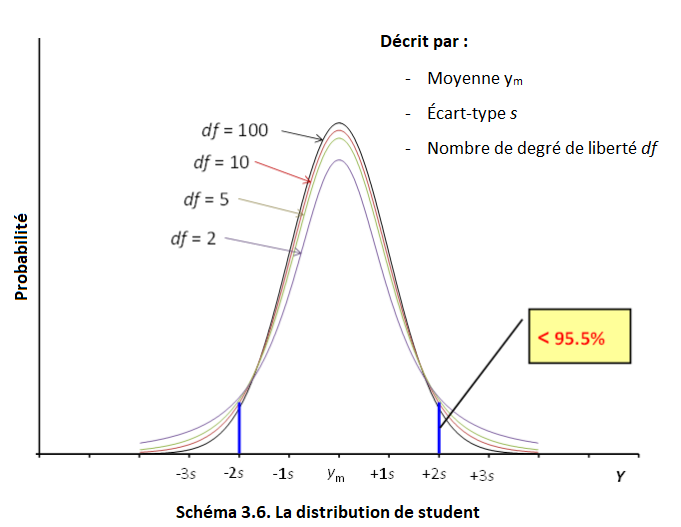
De manière similaire à la distribution normale, la distribution de Student a également une valeur moyenne ym et un écart type s. ym est la valeur moyenne elle-même [1] et l'écart-type est l'écart-type de la moyenne, calculé comme expliqué à la section 3.4. Mais, à la différence de la distribution normale, il existe une troisième caractéristique : le nombre de degrés de liberté df. Ce nombre est égal au nombre de mesures répétées moins un. Ainsi, les quatre graphiques de distribution de Student du schéma 3.5 correspondent respectivement à 101, 11, 6 et 3 mesures répétées.
Si df approche l'infini, la distribution t se rapproche de la distribution normale. En réalité, 30 à 50 degrés de liberté suffisent pour gérer la distribution t comme distribution normale. Ainsi, la courbe avec df = 100 dans le schéma 3.5 peut être considérée comme la courbe de distribution normale.
Plus le nombre de degrés de liberté est faible, plus les «queues» de la courbe de distribution de Student sont «lourdes» et plus la distribution est différente de la distribution normale. Cela signifie que plus de probabilité réside dans les queues de la courbe de distribution et moins dans la partie médiane. Il est important de noter que les probabilités représentées dans le schéma 3.2 pour les plages de ± 1, ± 2 et ± 3 s autour de la moyenne ne sont plus adaptées, mais sont toutes plus basses.
Ainsi, si un résultat de mesure est distribué selon la distribution t et si une incertitude élargie avec une probabilité de couverture prédéfinie est souhaitée, alors, au lieu des facteurs de couverture habituels 2 et 3, il convient d'utiliser les coefficients de Student respectifs [2]. Le résultat de la mesure peut être distribué en fonction de la distribution de Student s'il existe une source fortement prédominante [3] d'incertitude de type A qui a été évaluée en tant que valeur moyenne à partir d'un nombre limité de mesures répétées. Cependant, il est plus courant de constater qu’une source d’incertitude de type A, influente mais pas très dominante, existe. Dans un tel cas, la distribution du résultat de la mesure est une convolution [4] de la distribution normale et de la distribution t. La procédure à suivre dans ce cas est expliquée à la section 9.8.
Autoévaluation sur cette partie du cours : Test 3.6
https://sisu.ut.ee/measurement/measurement-1-4
***
[1] Il peut sembler étrange à première vue que, bien que la valeur moyenne ym soit la seule valeur moyenne dont nous disposions, nous la prenions immédiatement comme la valeur moyenne de la distribution des valeurs moyennes. Cependant, si nous avions plus de valeurs moyennes, nous les regrouperions dans une seule valeur moyenne (avec un df beaucoup plus élevé) Et utiliserions cette valeur.
[2] Les coefficients de Student (c.-à-d. Les valeurs de la distribution t) pour un ensemble donné de probabilité de couverture et le nombre de degrés de liberté peuvent être facilement obtenus à partir de tableaux spéciaux de manuels statistiques (utilisez des valeurs bilatérales!), À l'aide d'un logiciel de calcul ou de traitement de données. , tels que MS Excel ou Openoffice Calc ou sur Internet, par exemple de l'adresse https://en.wikipedia.org/wiki/Student_distribution
[3] Les contributions de différentes sources d'incertitude peuvent être exprimées numériquement. Ceci est expliqué dans la section 9.9 et les calculs respectifs sont présentés dans 9.7. Dans ce contexte, l'expression "fortement dominant" signifie que la contribution (indice d'incertitude) de la quantité d'entrée respective est supérieure à 75%.
[4] La convolution de deux fonctions de distribution en statistique mathématique désigne une combinaison de fonction de distribution, qui a une forme intermédiaire entre les deux fonctions de distribution convolutives.