MOOC Estimation des incertitudes de mesure en analyse chimique
7. Retour sur les effets aléatoires et systématiques
https://sisu.ut.ee/measurement/6-random-and-systematic-effects-revisited
Résumé : Ce chapitre explique que l’impact d’un effet sur les résultats de la mesure, de manière aléatoire ou systématique, dépend des conditions. Les effets systématiques à court terme peuvent devenir aléatoires à long terme. C'est la raison pour laquelle la répétabilité est, par sa valeur, inférieure à la reproductibilité intra-laboratoire, et que celle-ci est à son tour inférieure à l'incertitude-type composée. Cette section explique également que les estimations de l’incertitude des types A et B ne correspondent pas un à un aux effets aléatoires et systématiques.
Comment un effet intra-journalier systématique peut-il devenir un effet aléatoire à long terme ?
http://www.uttv.ee/naita?id=17713
| In one of the earlier lectures, I mentioned that the concept of random and systematic effects are not absolute concept and that, under certain conditions, systematic effects can become random effects, this is something we will now look at more carefully. Here is a scheme of a measurement result. We have here concentration axes and, on day one, we have obtained these results. We have made five repeated measurements on that day, and their values are here. And now, these values are affected both by random and by systematic effects, and we can see that the random effect causes the differences between these values. They do not agree among themselves. But the systematic effect we don't see from here, because all those values are shifted from each other. And now, there are a number of systematic effects that, from day to day, can be different, and this is exactly the case here. So let us look what happens if we now do the same measurement on more days. See on day 2, all measurements were shifted from the result of the 1, and on day 5, they were off by this much. On day 9, they are off to here etc ... So we see that within each of those numerous days, that are depicted here, the systematic effects has different direction and different magnitude, and this means that, in the context of many days, in the context of long term, this effect is not any more a systematic effect but is a random effect, and if we now look at the histogram, that is formed from all these results, then it in fact represents quite nicely the normal distribution function , which means that the systematic effect also gives its contribution into the scatter of the results. and if we looked at the data in long term, we can treat this systematic effect as a random effect, and we can determine its magnitude by repeating measurements on different dates. And this, is as we will see in the coming lectures, is a highly useful possibility for practical measurement uncertainty estimation. This example is also useful for distinguishing between repeatability and we didn't have long term reproducibility, or as it is also called intermediate precision. So the repeatability causes the scatter within things. So, for example, on this day, due to repeatability, the scatter is this wide. Or day number 9, the scatter is around this wide. On day number 17, with the scatter is like this on 29th. Day number 22, the scatter is this one. So, we see in all those cases, the scatter is roughly this much but if we look at all those results together, then the within lab long term reproducibility or intermediate precision characterizes the scatter over all those days. So that the scatter, if expressed as intermediate precision, is very much wider than the scatter expressed by repeatability, and it's easy to see why it is wider. Into repeatability, this systematic effect does not go in but, in the intermediate precision, this systematic effect is also included. Therefore, the standard deviation of repeatability is always smaller, and sometimes very much smaller than the standard deviation within that long-term reproducibility or, as it is called, intermediate precision. And here, we can visually characterize those standard deviations. Repeatability standard deviation amount roughly this width. And intermediate precision standard deviation this width or half of the width. | Dans l'une des précédentes vidéos, j'ai mentionné que les concepts d'effets aléatoires et systématiques ne sont pas des concepts absolus et que, sous certaines conditions, les effets systématiques peuvent devenir des effets aléatoires, qui est quelque chose que nous allons voir maintenant plus attentivement. Voici un graphique d'un résultat de mesure. Nous avons ici en abscisse l'axe des concentrations et, au jour 1, nous avons obtenu ces résultats. Nous avons effectué cinq répétitions de mesures ce jour là, et ces valeurs sont ici. Et maintenant, ces valeurs sont affectées par des effets aléatoires et systématiques, et nous pouvons voir que l'effet aléatoire provoque des différences entre ces valeurs. Il n'y a pas d'accord entre eux. Nous ne voyons pas l'effet systématique ici, car toutes ces valeurs sont décalés les unes des autres. Et maintenant, il y a un nombre d'effets systématiques qui, de jour en jour, peut être différent, et qui est exactement le cas ici. Regardons ce qu'il se passe si nous faisons maintenant la même mesure sur plus de jours. Regardez au second jour, toutes les mesures étaient décalées par rapport au résultat du premier jour, et le jour 5, elles étaient loin de ce point. Au jour 9, elles étaient encore plus loin etc... Nous voyons donc qu'avec chacun de ces nombreux jours, qui sont représentés ici, les effets systématiques ont une direction et une amplitude différente, et cela signifie que, dans un contexte de plusieurs jours, dans un contexte de long terme, cet effet n'est plus un effet systématique mais est un effet aléatoire, et si nous regardons maintenant l'histogramme, qui est crée avec tous ces résultats, alors il représente en fait assez bien la fonction de la distribution normale, qui signifie que l'effet systématique donne également sa contribution à la dispersion des résultats. Et si nous regardions les données sur le long terme, nous pouvons traiter cet effet systématique comme un effet aléatoire, et nous pouvons déterminer son amplitude en répétant des mesures à différentes dates. C'est, comme nous le verrons dans les vidéo à venir, une possibilité très utile pour l'estimation de l'incertitude de mesure. Cet exemple est aussi utile pour faire la distinction entre la répétabilité et la reproductibilité à long terme (nous n'en avions pas), aussi appelée fidélité intermédiaire. La répétabilité provoque donc la dispersion Donc par exemple, à ce jour, en raison de la répétabilité, la dispersion fait cette largeur. Ou alors le jour 9, la dispersion fait environ cette largeur. Le jour 17, la dispersion est équivalente à celle du jour 29. Le jour 22, la dispersion fait celle-ci. Donc, nous voyons que dans tous ces cas, la dispersion est équivalente mais si nous regardons tous ces résultats simultanément, alors la reproductibilité à long terme au sein du laboratoire ou la fidélité intermédiaire caractérise la dispersion sur tous ces jours. Donc la dispersion, si elle est exprimée par la fidélité intermédiaire, est beaucoup plus large que la dispersion exprimée par la répétabilité, et c'est facile de voir pourquoi la dispersion est plus large. Pour la répétabilité, l'effet systématique n'entre pas en compte mais, pour la fidélité intermédiaire, cet effet systématique est inclus. Par conséquent, l'écart-type de répétabilité est toujours plus petit, et parfois beaucoup plus petit que l'écart-type de reproductibilité à long terme ou, comme on l'appelle, la fidélité intermédiaire. Ici, nous pouvons caractériser visuellement ces écarts-types. L'écart-type de répétabilité correspond à peu près à cette largeur. L'écart-type de fidélité intermédiaire correspond à cette largeur ou à la moitié de cette largeur. |
Effets aléatoires et systématiques à court terme et à long terme
Un effet systématique sur une courte période (par exemple dans la journée) peut être aléatoire sur une plus longue période. Exemples:
- Si un certain nombre d'opérations de pipetage sont effectuées dans la journée en utilisant la même pipette, la différence entre le volume réel de la pipette et son volume nominal (c'est-à-dire l'incertitude d'étalonnage) sera un effet systématique. Si le pipetage est effectué à des jours différents et que la même pipette est utilisée, c'est également un effet systématique. Cependant, si le pipetage est effectué à des jours différents et que différentes pipettes sont utilisées, cet effet se transformera en effet aléatoire.
- Un instrument est étalonné quotidiennement avec des solutions d'étalonnage faites à partir de la même solution mère, qui est refaite tous les mois. Dans ce cas, la différence entre la concentration réelle de la solution mère et sa concentration nominale est un effet systématique en un jour et également en quelques semaines. Mais sur une période plus longue, disons une demi-année, [1] Il ne peut pas être strictement défini ce que signifie «à long terme». Une indication approximative pourrait être: un an, «plusieurs mois» (au moins 4-5) est minimum. Bien sûr, cela dépend aussi de la procédure. cet effet devient aléatoire, car un certain nombre de solutions mères différentes auront été utilisées pendant cette période.
Conclusions:
- Un effet systématique à court terme peut être aléatoire à long terme;
- Plus le délai est long, plus les effets peuvent passer de systématique à aléatoire.
Comme expliqué dans une vidéo précédente, si la mesure du même échantillon ou d'un échantillon identique est répétée dans des conditions identiques (généralement dans la même journée) en utilisant la même procédure, l'écart type des résultats obtenus est appelé écart type de répétabilité et noté sr. Si la mesure d'un échantillon identique ou identique est répétée en utilisant la même procédure mais dans des conditions modifiées selon lesquelles les changements sont ceux qui ont lieu en laboratoire dans des pratiques de travail normales, l'écart-type des résultats est appelé reproductibilité intra-laboratoire ou fidélité intermédiaire. et il est noté sRW. [2]
Les conclusions exprimées ci-dessus sont la raison pour laquelle sr est plus petit que sRW. Simplement, certains effets qui dans la journée sont systématiques et ne sont pas pris en compte par sr deviennent aléatoires sur une plus longue période et sRW les prend en compte. L'incertitude-type composée uc est à son tour supérieure à la fidélité intermédiaire, car elle doit prendre en compte tous les effets significatifs qui influencent le résultat, y compris ceux qui restent systématiques également à long terme. Cette relation importante entre ces trois quantités est visualisée dans le schéma 6.1.

Schéma 6.1. Relations entre la répétabilité, la reproductibilité intra-laboratoire et l'incertitude composée
Les effets aléatoires et systématiques ne peuvent pas être considérés comme étant en relation un à un avec l'estimation de l'incertitude de type A et B. Ce sont des choses catégoriquement différentes. Les effets se réfèrent aux relations causales intrinsèques, tandis que l'estimation de l'incertitude de type A et B se réfère plutôt aux approches utilisées pour quantifier l'incertitude. Le tableau 6 illustre cela davantage.

Ainsi, en fonction de la chronologie, tous les effets provoquant l'incertitude peuvent être regroupés comme illustré dans le schéma 6.2. À court terme, la plupart des effets agissent comme systématiques et les effets aléatoires peuvent être quantifiés via la répétabilité. À long terme, plus (généralement la plupart) des effets sont aléatoires et peuvent être quantifiés via la reproductibilité intra-laboratoire (fidélité intermédiaire).
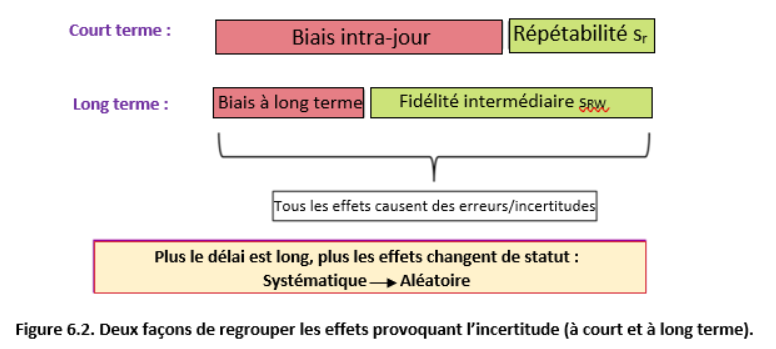
Comme expliqué dans le chapitre 8, les deux principales approches d'estimation de l'incertitude abordées dans ce cours utilisent les méthodes ci-dessus comme suit: L'approche de modélisation (ISO GUM) a tendance à suivre la vue à court terme (estimation de l'incertitude d'un résultat particulier sur un jour particulier), tandis que l'approche Single-lab (Nordtest) suit toujours la vision à long terme (estimation d'une incertitude moyenne de la procédure).
Déterminer la répétabilité et la reproductibilité intra-laboratoire en pratique
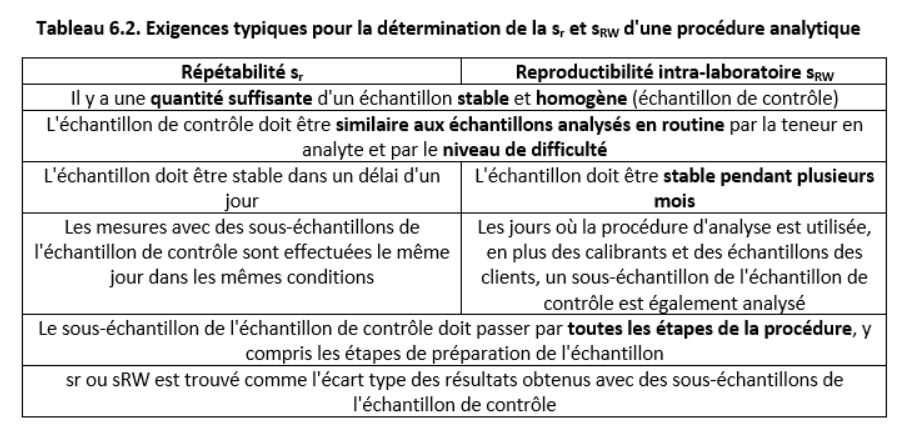
Les exigences types pour déterminer sr et sRW sont présentées dans le tableau 6.2.
Lors de l'estimation des contributions d'incertitude dues aux effets aléatoires, il est important d'effectuer un certain nombre de mesures répétées. D'un autre coté, si par exemple la répétabilité de certaines procédures analytiques doit être estimée, chaque répétition doit couvrir toutes les étapes de la procédure, y compris la préparation des échantillons. Pour cette raison, faire de nombreuses répétitions demande beaucoup de travail. Dans cette situation, le concept d'écart type groupé devient très utile. Son essence est la mise en commun des écarts-types obtenus à partir d'un nombre limité de mesures. La vidéo suivante explique cela:
Ecart type groupé
http://www.uttv.ee/naita?id=18228
| As we've seen already, whenever we want to determine precision meaning repeatability or within lab long-term reproducibility, it is always important to make many parallel measurements. And in fact, the more we make, the better estimate of precision we get. Now oftentimes chemical analysis can be quite work intensive. Meaning it's not easy to make many parallel measurements especially not within a short time period. And here a statistical tool called pooled standard deviation becomes very helpful for us. So a pooled standard deviation can be used both for repeatability and within lab reproducibility calculation. And the main formula of pooled standard deviation calculation is here. So in the case of pooled standard deviation we always make measurements with several samples. And in this formula, these numbers here denote the sample numbers. So we have all together K samples. And each s is the standard deviation of that particular sample. S1 the standard deviation of the first, s2 of the second sample and so on. And n stand for the number of parallel measurements made with those samples. So all these standard deviations that we get with individual samples, we take to the square multiplied by the number of parallel measurements that we made minus one add all of them up and then divide by this kind of number, which is in fact the sum of all the parallel measurements numbers minus the number of samples. And what we eventually get is the pooled standard deviation. The good thing about pool standard deviation is that you can involve a large number of samples at the same time with each samples the number of measurements can be very small. In fact it is enough if with each sample just two measurements are made as long as you have many samples. And the number of degrees of freedom for pooled standard deviation is in fact this number here. So that if we have let's say ten samples but make with each of them only two measurements, then this number of degrees of freedom will be 10 times 2 minus 10 which is equal to 10. Meaning it's roughly statistically speaking as good as making 11 parallel measurements with the same sample. So, even though each of those standard deviations which are found from just two parallel measures is very very very very unreliable but if we have many of them and we average them according to this formula, then the resulting pooled standard deviation will be quite reliable in fact. It is important that all those samples that we carry out the measurements with, have to be similar. So that it has to be expected that their standard deviations are roughly comparable, roughly the same. If the samples have very different concentration levels, very different matrixes, very different level of difficulty of sample preparation, then the resulting pooled standard deviation will not carry much meaning. Now on the other hand, if we compare standard deviation that is obtained as a pooled standard deviation from a number of different samples, with in the case where with all the samples we make not so many parallel measurement, or the second case where we have just one single sample, and we make a large number of measurements with that samples, then in fact the pooled standard deviation can give us more reliable precision estimate because the properties of the slightly different samples will all be taken into account. So that the pooled standard deviation indeed will be an average standard deviation over all these samples. And secondly, usually those standard deviations are found on different days. Meaning on one day perhaps our instrument is in better working order on the other day it's in slightly worse working order. Again the resulting pooled standard deviation gives us the average situation in our lab. If we make standard deviation determination on just one day with just one sample, then it can one happen that this particular sample is a specifically good sample and the instrument on that they can be in a very good working condition which can result in a very low standard uncertainty which is a repeatability standard uncertainty in this case. And this can give us two optimistic estimate for the future use because whenever we determine such standard deviation we do this for using it in the future for some measurement uncertainty calculation. In a contrast pooled standard deviation gives us the average situation in our laboratory and this in fact more reliable in that respect. We see from this formula that with every sample we can meet a different number of measurements. For one sample we can make maybe two with the other one five etcetera. And this is fully okay these different standard deviations then will be taken into account by different weights. So all these n minus ones here can be regarded as different statistical weights. If however, the measurement was organized in such a way that the number of measurement with each of the samples was the same, then the formula becomes simpler and the numbers of measurements can be omitted all together. I mentioned that both repeatability and within lab long-term reproducibility can be evaluated with pooled standard deviation. And let us see now how to set such experiments up in practice. | Comme nous l'avons déjà vu, chaque fois que nous voulons déterminer la fidélité, c’est-à-dire la répétabilité ou la reproductibilité intra-laboratoire, il est toujours important de faire plusieurs mesures en parallèle. Et en fait, plus on fait de mesures et plus on aura une bonne estimation de la fidélité. Souvent, les analyses peuvent être assez denses. Ce qui veut dire qu'il n'est pas facile de faire beaucoup de mesures en parallèle, notament dans un court laps de temps. Dans cette situation, un outil statistique appelé écart-type groupé devient très utile pour nous. En effet, l'écart type groupé peut-être utilisé à la fois pour le calcul de la répétabilité et de la reproductibilité intra-laboratoire. La principale formule de l'écart-type groupé est ici. Dans le cas de l'écart type groupé, on réalise toujours les mesures avec plusieurs échantillons. Et dans cette formule, ces nombres ici représentent le numéro d'échantillon. Donc nous avons jusqu’à k échantillons. Et chaque s est l'écart-type de chaque échantillon. S1 correspond à l'écart type de l'échantillon 1, s2 l'écart-type de l'échantillon n°2, etc… Donc n désigne le nombre de mesures parallèles faites avec chaque échantillon. Donc, tous ces écarts-types que l'on obtient pour chaque échantillon, on les élève au carré, on les multiplie par le nombre de mesures faites en parallèle moins 1. Ces quantités sont ensuite sommées entre elles et on les divise par ce nombre, qui est en fait la somme de TOUTES les mesures faites en parallèle (sur tous les échantillons) moins le nombre d'échantillons. Et ce qu'on finit par obtenir, c'est l'écart-type groupé. Ce qui est intéressant à propos de l'écart-type groupé, c'est que vous pouvez avoir un grand nombre d' échantillons et pour chacun d'entre eux le nombre de mesures faite peut être très petit. En fait, c'est suffisant si avec chaque échantillon, au moins 2 mesures sont réalisées tant qu'il y a beaucoup d'échantillons (sur lesquels faire les mesures). Le nombre de degrés de liberté pour l'écart type groupé est en fait ce nombre ici. Donc, si nous avons disons 10 échantillons mais qu'on ne fait avec chacun d'entre eux que 2 mesures, alors ce nombre de degrés de libertés vaudra 10*2 - 10, ce qui est égal à 10. Ce qui veut dire que c'est, statistiquement parlant, environ aussi bien que 11 mesures parallèles faites sur le même échantillon. Donc, bien que chacun de ses écarts-types, qui sont obtenus à partir de 2 mesures parallèles, soient très, très, très, très peu fiables, mais si nous en avons beaucoup (d'écarts-types) et que nous les moyennons selon cette formule, alors l'écart-type groupé résultant sera assez fiable en fait. C'est très important que tous ces échantillons sur lesquels nous avons réalisé les mesures, doivent être similaires. C'est à dire que leurs écarts-types doivent être semblables et similaires. Si les échantillons ont des niveaux de concentrations différents, des matrices très différentes, ou des niveaux de difficultés de préparation d'échantillon très différents, alors l'écart-type groupé résultant ne signifiera pas grand-chose. Maintenant, si nous comparons l'écart-type qui est en fait l'écart-type groupé obtenu à partir d'un nombre différent d'échantillons dans le cas ou peu de mesures en parallèle ont été effectuées sur chaque échantillons avec le deuxième cas où on ne posséderait qu'un seul échantillon et où on ferait un grand nombre de mesure, alors, en fait, l'écart-type groupé (obtenu dans le 1er cas) peut nous donner une estimation plus fiable de la fidélité car les propriétés un peu différente de chaque échantillons seront toutes prises en compte. Ce qui fera que, l'écart-type groupé sera, effectivement, un écart-type moyen de tous les échantillons. Et de plus, souvent, ces écarts-types sont estimés sur plusieurs jours. En effet, pour un jour, peut-être que notre appareil de mesure peut marcher un peu mieux mais un autre jour, un peu moins bien. À nouveau, l'écart-type groupé résultant nous donne une moyenne des conditions expérimentales dans notre laboratoire. Si nous déterminons un écart-type sur un seul jour avec un seul échantillon, alors il peut arriver que cet échantillon en particulier soit un bon échantillon et l'appareil, sur ce jour, peut également être dans de très bonnes conditions de fonctionnement, ce qui peut alors donner une très faible incertitude type qui est également l'incertitude type de répétabilité dans ce cas. Cela donne 2 "bonnes" incertitudes pour de futures applications car lorsque nous déterminons ces écarts-types, nous le faisons afin de pouvoir les réutiliser plus tard, dans le temps, pour des calculs d'incertitudes de mesurages. Alors que l'écart-type groupé, nous donne une situation moyenne de notre laboratoire ce qui est en fait plus fiable. Nous voyons, sur cette formule qu'avec chaque échantillon, nous pouvons avoir un nombre différent de mesures. Pour un échantillon, on peut faire peut-être 2 mesures, mais avec un autre plutôt 5 mesures, etc… Et cela est totalement valide car les différents écarts-types obtenus seront ensuite pondérés par différents poids. Donc tous ces n moins 1 (n-1) ici peuvent être vu comme différents poids statistiques. Si, cependant, les mesures étaient organisées de telle manière que le nombre de mesures de chaque échantillons soit le même, alors la formule devient plus simple et le nombre de mesures de chaque échantillon peut se factoriser. J'ai évoqué plus tôt que la répétabilité et la reproductibilité intra-laboratoire peuvent être évaluées à l'aide de l'écart-type groupé. Regardons maintenant comment mettre en pratique cet objectif. |
Selon la façon dont les expériences sont planifiées, l'écart type groupé peut être utilisé pour calculer la répétabilité sr ou la reproductibilité intra-laboratoire sRW.
Le plan expérimental et les calculs lors de la recherche de répétabilité sr sont expliqués dans la vidéo suivante:
Ecart type groupé en pratique : estimation de la répatabilité
http://www.uttv.ee/naita?id=18232
| I mentioned that both repeatability and within lab long-term reproducibility can be evaluated with pooled standard deviation, and let us see now how to set such experiments up in practice. Let us look now how the experimental logic will look like if we want to estimate repeatability from pooled standard deviation. I will explain this with a graph. On one axis of the graph, we will have samples, and on the other axis we have days. And suppose we have four different samples. One, two, three, four. And now since with each of the sample, for correct repeatability estimation we have to carry out the full analytical procedure including also the sample preparation, then we cannot make many many many measurements within a single day. But suppose on day one we work with sample number one and we make all together four measurements with it. One, two, three, four. On day two, we work with sample number three and we make three measurements with it. Let me also mark the days here. On day three we will work with sample number two, and we will make five mesurements. And finally on day four we will work with sample number four, and we will make two measurements. So from each of these sets of measurements, we can calculate repeatability for this particular sample on this particular day. Of course, obviously these days do not need to be consecutive days, they can be far apart from each other separated by several weeks. Now, in this particular case n1 will be 4, n2 will be 5, n3 will be 3 and n4 will be 2. And if we add all these numbers up, we will get : 4 plus 5 equal to 9, plus 3 equal to 12, plus 2 equal to 14, and if we subtract from this the number of samples, which is 4, we get 10 which will be for us the number of degrees of freedom. Meaning the pooled standard deviation calculated by this approach, corresponds to the situation as if we had made 11 measurements within a single day on one single sample. But as I explained previously, this approach, in fact, gives you a more reliable repeatability estimate. It goes different sample envolved which can be slightly different, by their matrix or by the difficulty of analysis, and also different days are involved, meaning the laboratory settings can be slightly different. Let us look now at the practical calculation of pooled standard deviation from the example of determination of an antibiotic, meropenem, in blood plasma by HPLC. And here are the data which exactly correspond to the situation which I just showed on the whiteboard. So different days, different samples and different numbers of parallel measurements. And I have also incorporated here into the slide, the formula by which the pooled standard deviation is calculated. And we will first start by calculating the standard deviations for all the samples and also by writing the numbers of n-1 for all the samples. So standard deviation expressed in µg/g. And I will mark the area, in such a way that it would be suitable for each and every of this column. Those empty cells will be omitted by the STDEV function so they will not be considered by test zeros so the calculations will be correct So these are now the individual standard deviations. Now it's useful to write here the n-1 values. In this case it's 3, in this case it's 2, in this case it's 4, in this case it's 1. And now it's useful to make a row where the n-1 is multiplied by the standard deviation squared. n-1 multiplied by s squared. So… Now we have all the data needed for calculating the pooled standard deviation, and let me just comment on the denominator of this ratio here. If we sum up n1, n2, etc... and subtract then the K, then in fact this will be exactly the same as the sum of the n-1 and since we have the n-1 values nicely available here, we will in fact instead of this use the sum of n-1 values for the calculation. So it's a repeatability pooled standard deviation and is equal to square root, and it now is a ratio of two sums : sum of these products here divided by the sum of all the n-1 values here. And of course, it is expressed in the same way in µg/g. So if we want to characterize this procedure by repeatability estimate, then this repeatability estimate would be most suitable, because it has been determined with different samples on different days. And it is important to mention that even though the days are different, since on each day we have the standard deviation which gives us repeatability because all the measurements were done on the same day, then all this are repeatability standard deviations and when we pool repeatability standard deviation we also get repeatability standard deviation. So even though the experiments were carried out on different days we do not get reproducibility but we get repeatability standard deviation. | J'ai mentionné que la répétabilité et la reproductibilité à long terme en laboratoire peuvent être évaluées avec l'écart-type global et voyons maintenant comment mettre en place de telles expériences en pratique. Regardons maintenant à quoi va ressembler la logique expérimentale si l'on veut estimer la répétabilité à partir de l'écart-type global. Je vais expliquer cela avec un graphique. Sur un axe du graphique nous aurons les échantillons, et sur l'autre axe nous avons les jours. Et supposons que nous ayons quatre échantillons différents. Un, deux, trois, quatre. Et maintenant puisque pour chaque échantillon, pour une estimation correcte de la répétabilité, nous devons effectuer la procédure d'analyse complète incluant la préparation des échantillons, alors nous ne pouvons pas faire beaucoup beaucoup beaucoup beaucoup de mesures dans une même journée. Mais supposons que le premier jour nous travaillons avec l'échantillon numéro un et nous faisons tous ensemble quatre mesures avec lui. Un, deux, trois, quatre. Le deuxième jour, nous travaillons avec l'échantillon numéro trois et nous faisons trois mesures avec lui. Permettez-moi aussi de marquer les jours ici. Le troisième jour, nous travaillerons avec l'échantillon numéro deux et nous allons faire cinq mesures. Et enfin, le quatrième jour, nous travaillerons avec l'échantillon numéro quatre et nous ferons deux mesures. Donc à partir de chacun de ces ensembles de mesures, nous pouvons calculer la répétabilité pour cet échantillon particulier en ce jour particulier. Bien sûr, il est évident que ces jours ne doivent pas nécessairement êtrs des jours consécutifs, ils peuvent être très éloignés les uns des autres, séparés par plusieurs semaines. Maintenant dans ce cas particulier n1 sera 4, n2 sera 5, n3 sera 3 et n4 sera 2. Et si nous ajoutons tous ces chiffres, nous obtenons : 4 plus 5 égal à 9, plus 3 égal à 12, plus 2 égal à 14, et si nous soustrayons à ceci le nombre d'échantillons, qui est de 4, que nous obtenons 10 qui sera pour nous le nombre de degrés de liberté. Cela signifie que l'écart type global calculé par cette approche, correspond à la situation où nous aurions fait 11 mesures en un seul jour sur un seul échantillon. Mais comme je l'ai expliqué précédemment, cette approche, en fait, nous fournie une estimation plus fiable de la répétabilité. Elle implique différents échantillons qui peuvent être légèrement différents, de part leur matrice ou de part la difficulté d'analyse, et aussi différents jours sont impliqués, ce qui signifie que les paramètres de laboratoire peuvent être légèrement différents. Examinons maintenant les aspects pratiques du calcul de l'écart type global à partir de l'exemple de la détermination d'un antibiotique, le méropénem, dans le plasma sanguin par HPLC. Et voici les données qui correspondent exactement à la situation que je viens de montrer sur le tableau blanc. Donc différents jours, différents échantillons et différents nombres de mesures parallèles. Et j'ai également intégré ici dans la feuille, la formule avec laquelle l'écart type global est calculé. Et nous allons commencer par calculer l'écart-type pour tous les échantillons et aussi en écrivant les valeurs de n-1 pour tous les échantillons. L'écart-type est exprimé en µg/g. Et je vais marquer la zone de manière appropriée pour chacune de ces colonnes. Ces cellules vides seront omises par la fonction STDEV, de sorte qu'elles ne seront pas pris en compte par le test zéro, de manière à ce que les calculs soient correctes. Ainsi, ce sont alors les écarts types individuels. Il est maintenant utile d'écrire ici les valeurs n-1. Dans ce cas c'est 3 dans ce cas c'est 2, dans celui-ci c'est 4, dans celui-là c'est 1.Et maintenant il est utile de faire une ligne où le n-1 moins 1 est multiplié par l'écart-type au carré. n-1 multiplié par s au carré. Donc… Nous avons maintenant toutes les données nécessaires pour calculer l'écart-type global et laissez-moi juste commenter le dénominateur de ce rapport ici. Si nous additionnons n1, n2, etc ... et soustrayons alors le K, alors en fait ce sera exactement la même valeur que la somme des n-1 et comme nous avons les valeurs de n-1 bien disponibles ici, nous utiliseront en fait à la place de ceci, la somme des valeurs de n-1 pour le calcul. Il s'agit donc d'un écart-type global de répétabilité et c'est égale à la racine carrée, et c'est maintenant un rapport de deux sommes : somme de ces produits ici divisés par la somme de toutes les valeurs de n-1 ici. Et bien entendu, il est exprimé de la même façon en µg/g. Donc si nous voulons caractériser cette procédure par une estimation de la répétabilité, alors cette estimation de répétabilité serait la plus approprié, parce qu'elle a été déterminée avec des échantillons différents sur des jours différents. Et il est important de mentionner que bien que les jours soient différents, puisque pour chaque jour, nous avons l'écart type ce qui nous donne une répétabilité car toutes les mesures ont été effectuées sur le même jour, alors tout cela est l'écart-type et quand nous globalisons l'écart type de répétabilité on obtient aussi l'écart type de répétabilité. Donc même si les expériences étaient effectuées à des jours différents, nous ne pourrions pas obtenir la reproductibilité, mais nous obtenons écart-type de répétabilité. |
Le plan expérimental et les calculs lors de la recherche de la reproductibilité sRW en laboratoire sont expliqués dans la vidéo suivante:
Ecart-type groupé en pratique : estimation de la reproductibilité à long terme en laboratoire
http://www.uttv.ee/naita?id=18234
| Let us look now, how to set up the experiment for determining within-lab long-term reproducibility from Pooled Standard Deviation. And again we will make a graph and again we will have samples on one axis, and suppose we can have 4 samples. And now on the other axis, we again have days but this time, we need more days and we need them certainly spread over a long time period. So let us take for example 9 different days. And again, we analyze each sample. But now, we do not analyze the sample on the same day but we will spread out the analysis across a number of days. And let's assume that sample number 1 was analyzed on day 1, one day 4 and on day 8. Sample number 2 was analyzed on day 2, day 4, day 6 and day 9. Sample number 3 was analyzed on day 1, day 3, day 5 and day 7. And finally, sample number 4 was analyzed on day 3, day 6, day 8. So we see now that on each day different samples were analyzed and also on each day, only one analysis was done but each of the samples got analyzed across a long time period because the time between each consecutive pair of days can be few weeks. So that this whole time period can easily be maybe a half of year or even a year. So it will really be a long-term reproducibility standard deviation. But now, with each sample again, we can make quite few measurements, no so many, but since we averaged across all these measurements, eventually our Pooled Standard Deviation statistically will be quite reliable. And again of course, the averaging, here, comes from the fact that we have somewhat different samples and obviously different days. Let us look now, how the calculation within-lab long-term reproducibility from Pooled Standard Deviation can be done practice. And we will again look at this on an example and this time it will be protein content determination by the Kjeldahl method. We see here now that we have several samples, five altogether. And each of these samples has been measured on several different days and those days are separated quite far apart from each other so that up to half a year time is involved in this determination. And here, we can see the results of those determinations that were obtained for these several sums. And again, it is useful to first of all calculate the standard deviation for each of these samples and then the "n-1" values and then the products of "n-1" to standard deviation squared. And then finally, we can calculate the Pooled Standard Deviation according to this form. So this time, we will organize these data in columns because this is more reasonable with this arrangement of data. Standard deviations in g/100g and we will also put here sample numbers. So for sample 1, it will be like this. For example 2, we'll get this one. For sample 3, like this. For sample 4, this one. And for sample 5, our standard deviation will be like this. Now "n-1", for sample 1, it's 2. Sample 2 also 2. Sample 3 also 2. Sample 4 also 2. And sample 5, it's 1. And now, these products "n-1" multiplied by standard deviation squared. And here, we can now copy and again as we saw in the case of repeatability calculation, we can now calculate the Poor Standard Deviation, a square root of the sum of all these components divided by the sum of the n minus 1 values which as I explained, will be exactly equal to this value here. So within-lab long-term reproducibility pooled standard deviation will be here, square root sum of all these components divided by the sum of all "n-1 values and the unit of course is g/100g. And this can now be used conveniently for characterizing the procedure for uncertainty estimation using the nordtest approach!. And it's a reliable standard deviation because it has been obtained over a long time period and also with different samples which means averaging. And the number of degrees of freedom in this particular case is altogether 9 which is the sum of these values. And of course, if the laboratory continues working in this field then it's very useful to collect more and more data, either to reanalyze these samples if it is still possible or to collect more data so that to make this standard deviation estimate still more reliable. | Voyons maintenant, comment mettre en place l'expérience pour déterminer la reproductibilité intra-laboratoire à long terme par l'écart-type groupé. Et encore une fois nous allons faire un graphique et nous aurons de nouveau des échantillons sur un axe, et supposons que nous puissions avoir 4 échantillons. Et maintenant sur l'autre axe, nous avons encore des jours mais cette fois, nous avons besoin de plus de jours et nous en avons certainement besoin sur une longue période. Prenons donc comme exemple 9 jours différents. Et à nouveau, nous analysons chaque échantillon. Mais désormais, nous n'analysons pas l'échantillon le même jour mais nous allons étaler l'analyse sur plusieurs jours. Et supposons que l'échantillon 1 a été analysé le jour 1, le jour 4 et le jour 8. L'échantillon numéro 2 a été analysé le jour 2, le jour 4, le jour 6 et le jour 9. L'échantillon numéro 3 a été analysé le jour 1, le jour 3, le jour 5 et le jour 7. Et finalement, l'échantillon numéro 4 a été analysé le jour 3, le jour 6, le jour 8. Nous voyons donc maintenant que chaque jour différents échantillons ont été analysés et aussi que chaque jour, seulement une analyse a été réalisée. mais chacun des échantillons ont été analysé sur une longue période car le temps entre chaque pair de jours consécutifs peut être quelques semaines. De telle sorte que cette période puisse être facilement un semestre ou même une année. Cela serait vraiment un écart-type de reproductibilité à long terme. Mais maintenant, avec chaque échantillon, de nouveau, nous pouvons faire assez peu de mesures, pas tant que cela, mais étant donné que nous faisons la moyenne de toutes ces mesures, notre écart-type groupé sera finalement assez fiable statistiquement. Et encore une fois bien sûr, la moyenne, ici, vient du fait que nous avons des échantillons quelque peu différents et évidemment de jours différents. Voyons maintenant, comment le calcul de la reproductibilité intra-laboratoire à long terme à partir de l'écart-type groupé peut être réalisé en pratique ? Et nous allons le voir dans un exemple et cette fois ce sera la détermination de la teneur en protéines par la méthode de Kjeldahl. Nous voyons ici que maintenant nous avons plusieurs échantillons, 5 au total. Et chacun de ces échantillons a été mesuré sur plusieurs jours et ces jours sont séparés assez loin les uns des autres de sorte qu'un temps d'une demie-année soit pris en compte dans cette détermination. Et ici, nous pouvons voir les résultats de ces déterminations qui ont été obtenus pour ces plusieurs sommes. Une fois encore, il est utile de d'abord calculer l'écart-type pour chacun de ces échantillons et ensuite les valeurs de "n-1" et puis le produit de "n-1" par l'écart-type au carré. Et finalement, nous pouvons calculer l'écart-type groupé en utilisant cette formule. Donc cette fois, nous allons organiser ces données dans des colonnes parce que cela est plus judicieux avec cette dispositon de données. L'écart-type en g/100g et nous pourrons mettre ici de simples nombres. Donc pour l'échantillon 1, ce sera comme cela. Pour l'échantillon 2, nous allons mettre cela. Pour l'échantillon 3, comme ceci. Pour l'échantillon 4, ceci. Et pour l'échantillon 5, notre écart-type sera comme cela. Maintenant "n-1", pour l'échantillon 1, c'est 2. L'échantillon 2 aussi 2. L'échantillon 3 aussi 2. L'échantillon 4 aussi 2. Et l'échantillon 5, c'est 1. Et maintenant, ces produits : "n-1" multipliés par l'écart-type au carré. Et ici, nous pouvons maintenant copier et de nouveau comme nous avons vu dans la case de calcul de répétabilité, nous pouvons désormais calculer l'écart-type groupé, une racine carrée de la somme de tout ces composants divisée par la somme des valeurs "n-1" qui comme je l'ai expliqué, sera exactement égal à cette valeur là. Donc l'écart-type groupé de la reproductibilité intra-laboratoire à long terme sera ici, la racine carrée de la somme de tous ces composants divisée par la somme de toutes les valeurs "n-1" et l'unité est bien sûr le g/100g. Et cela peut être utilisé convenablement pour caractériser la procédure de l'estimation des incertitudes utilisant l'approche Nordtest. Et c'est un écart-type fiable car il a été obtenu sur une longue période et aussi avec différents échantillons qui signifie une moyenne. Et le nombre de degrés de liberté dans ce cas particulier est au total 9 qui est la somme de ces valeurs. Et bien sûr, si le laboratoire continue de travailler dans ce domaine alors c'est très utile de collecter de plus en plus de données, soit pour analyser de nouveau ces échantillons si cela reste possible ou pour collecter plus de données pour faire que cet écart-type estimé reste plus fiable. |
Autoévaluation sur cette partie du cours : Test 6
https://sisu.ut.ee/measurement/measurement-1-3
***
[1] Il ne peut pas être strictement défini, combien de temps est «à long terme». Une définition approximative pourrait être: un an, c'est bien, «plusieurs mois» (au moins 4-5) est le minimum. Bien sûr, cela dépend aussi de la procédure.
[2] Les termes «reproductibilité intra-laboratoire» et «fidélité intermédiaire» sont synonymes. Le VIM (1) préfère la fidélité intermédiaire. Le manuel Nordtest (5) utilise la reproductibilité intra-laboratoire. Afin de souligner l'importance du «long terme», dans ce cours, nous appelons souvent sRW la reproductibilité à long terme en laboratoire.
***
Les diapositives de la présentation et des fichiers de calcul - avec les données initiales uniquement, ainsi qu'avec les calculs effectués - sont disponibles ici:
Ecart-type groupé - répétabilité - données initiales.xls
Ecart-type groupé - répétabilité - résolu.xls
Ecart-type groupé - reproductibilité - données initiales.xls
Ecart-type groupé - reproductibilité - résolu.xls