MOOC Estimation des incertitudes de mesure en analyse chimique
4. Les concepts et outils fondamentaux
4.1. La fonction normale de distribution
https://sisu.ut.ee/measurement/31-normal-distribution
Résumé : Ce cours commence par généraliser que toutes les valeurs mesurées sont des quantités aléatoires du point de vue de la statistique mathématique. La distribution la plus importante en science de la mesure - la distribution normale - est ensuite expliquée : son importance, les paramètres de la distribution normale (moyenne et écart type). Les définitions initiales d'incertitude type (u), d'incertitude élargie (U) et de facteur d'élargissement (k) sont données. Un lien entre ces concepts et la distribution normale est créé.
La distribution normale
http://www.uttv.ee/naita?id=17589
| From the point of view of mathematical statistics, our measured quantities are actually random quantities. And random quantities are described by distribution functions. And when we deal with measurement science, then the most important distribution function for us is the normal or the Gaussian distribution. And because of certain laws of nature, whenever a process or a result is influenced by many factors, then the more factors we have that influence, the nearer the distribution function of that result becomes to the normal distribution. Therefore, very often measurement results are distributed normally, and the large part of the mathematics that is used in measurement science is based on the properties of the normal distribution. The normal distribution function curve is depicted in this slide. It characterizes the probability of a random quantity, and the random quantity is Y in our case. And the probability is on the vertical axis. And this distribution function tells us that there's a certain most probable value, the mean value Yn, where the probability of this random quantity occurring is highest. And as we depart from the mean value to either of these two sides, the probability gradually decreases. So that this is basically a probability density graph; the highest probabilities in the middle, the lowest on the sides. There are some important properties of this distribution function. First of all, even though the probability gradually decreases and actually quite sharply decreases as we move away from the main value, it never really becomes a zero. So there will also always be some positive nonzero probability. And this is the main reason why usually we cannot give measurement uncertainties 100% probability that we saw in another lecture. This normal distribution function property actually tells us that this is impossible. Now the second important feature this normal distribution curve is that even though it never really ends. so there always will be positive value however far we move from the mean value. Nevertheless, the area, the area under this curve is finite, and in the case of normalized function, it's equal to unity. Meaning the probability of this value being somewhere is 100%, which obviously needs to be true. Now let us examine the normal distribution function work closely on the example of pipetting. So we have a 10 mL pipette and suppose we pipette several times, trying to pipette ten milliliters every time. What happens? What happens is that every time, we get a slightly different value. So, see, it's always somewhere near ten milliliters, but never exactly ten. And also, it tends to be quite different, different. If we now plot these values as a histogram, then, we see something like this. This histogram in principle should resemble the beautiful bell-shaped curve that we just saw. But we see that it is, in fact, very different. The reason is obvious: we have only made ten measurements up to now, and ten measurements is a too small number to get the normal distribution curve. Let us also look at this axis here, it's now not probability, but frequency. Probability and frequency are closely connected to each other. Basically, the higher the probability, the higher the frequency of a certain measurement result occurring within a certain volume. Let us examine now what happens if we make more measurements. So as the measurements come, we see that they tend to come into the center part more often than on the sides. We can see that if we now make 27 measurments, then even though we still don't have this nice bell-shaped curve we already now have more measurement results in the middle and less measurement results on the sides. So that the number of measurement is increasing and this distribution function depicted here by histogram becomes more normal distribution like. But if we now make many a very large number of measurements, let's say 1,000 then our histogram really will resemble the normal distribution very nice. It is not really easy to make 1,000 measurements whatever the measurement is. But luckily we do not need nearly as many measurements to get the important characteristics of the normal distribution. So usually we do not need to record this shape as such. We simply need to know some important characteristics or important parameters. And those most important characteristics of parameters are two. The mean value, which characterizes the position of this curve, and the standard deviation S which characterizes its width or the scatter of the results. So the smaller the standard deviation, the smaller the scatter of the results. And now, with the use of this curve, we can make some very important observations about its nature. So we can see that if we move from the mean value away by one standard deviation to either of the sides, then we get a contour of this shape. I turns out, from the properties of the normal distribution function, that the ratio of this area to the overall area under this normal distribution curve, is a roughly 68%. This is the basis of definition of standard uncertainty. So standard uncertainty, as we see in many cases in other lectures, is the uncertainty given at one standard deviation level and also it's there by uncertainty at roughly 68% probability. Now we can multiply this standard deviation by some factor and if we multiply it by two, then we get this kind of curve. And now the area of this part here as related to the whole area under the normal distribution curve makes up roughly ninety five point five percent. And this here forms the basis of the so called expanded uncertainty. So expanded uncertainty, as we can see in other lectures, is obtained by multiplying standard uncertainty with some coverage factor. Two in this case. And it allows us, enables us obtaining measurement uncertainty estimate with higher probability. So this 2's level or as we say expanded uncertainty at k2 level, is uncertainty at roughly 95,5% probability. So the probability of the true value falling within this range is now significantly high. And likewise, if we multiply S by 3 then the same percentage will be 99.7% | Du point de vue des statistiques mathématiques, les quantités que nous mesurons sont en fait des quantités aléatoires. Les quantités aléatoires sont décrites par des fonctions de distribution. Quand nous avons affaire à la science de la mesure, alors la fonction de distribution la plus importante pour nous est la loi normale ou la distribution Gaussienne. À cause de certaines lois naturelles, lorsqu'un procédé ou un résultat est influencé par plusieurs facteurs, alors, plus on a de facteurs qui ont une influence, plus la fonction de distribution du résultat tend vers une distribution normale. Par conséquent, les résultats de mesure sont très souvent distribués suivant la loi normale. La plupart des lois mathématiques qui sont utilisées dans la science de la mesure sont basées sur des propriétés de la distribution normale. La courbe de la fonction de distribution normale est illustrée dans cette diapositive. Elle caractérise la probabilité d'une quantité aléatoire, qui est dans notre cas Y. La probabilité est sur l'axe vertical. Cette fonction de distribution nous dit qu'il existe une certaine valeur, la plus probable, la valeur moyenne Yn, où la probabilité que cette quantité aléatoire se produise est maximale. À mesure que nous nous éloignons de la valeur moyenne de part et d'autre, la probabilité diminue progressivement. Il s'agit donc d'un graphique de densité de probabilité avec au milieu, les plus grandes probabilités et les plus faibles sur les côtés. Il existe des propriétés importantes de cette fonction de distribution. Premièrement, même si la probabilité diminue progressivement et plutôt rapidement en s'écartant de la valeur moyenne, elle n'est jamais égale à zéro. Donc il y aura toujours des valeurs de probabilités positives et non nulles. C'est la raison pour laquelle on ne peut pas donner des incertitudes de mesures avec une probabilité de 100% comme nous l'avons vu dans d'autres cours. Cette propriété de la fonction de distribution normale nous dit donc que cela est impossible. La deuxième caractéristique importante de cette courbe de distribution normale est que même si elle ne se termine jamais, il y a donc toujours une valeur positive peu importe à quel point on s'éloigne de la valeur moyenne. Toutefois, l'aire sous la courbe reste finie. Dans le cas de la fonction normale elle est égale à 1. Ce qui signifie que la probabilité de cette valeur d'être quelque part est de 100%, ce qui est, évidemment, un fait. Maintenant, examinons de plus près la fonction de distribution normale qui s'applique ici à l'exemple du pipettage. Nous avons donc une pipette de 10 mL et supposons que nous avons voulu pipetter plusieurs fois en essayant de pipetter 10mL à chaque fois. Que se passe-t-il ? Ce qui se passe, c'est qu'à chaque fois on a une valeur légèrement différente. Nous pouvons voir que c'est toujours autour de 10mL mais jamais exactement 10. Cela a tendance à être différent. Si maintenant, nous relevons les données et que nous en faisons un histogramme, nous observons quelque chose comme ça. Cet histogramme devrait en principe ressembler à la belle courbe en forme de cloche que l'on vient de voir. Mais on constate que c'est très différent. La raison est évidente, nous avons seulement fait 10 mesures jusqu'à maintenant et c'est un nombre trop petit pour avoir une courbe de distribution normale. Regardons aussi cet axe (vertical), il ne s'agit plus de probabilités mais de fréquences. Probabilités et fréquences sont étroitement connectées car plus la probabilité est grande, plus la fréquence d'une certaine mesure de volume est élevée. Intéressons nous maintenant à ce qu'il se produit lorsque nous effectuons plus de mesures. Au fil des mesures, les valeurs de volume tendent plus souvent vers la partie centrale que vers les côtés. Si nous réalisons à présent 27 mesures, même si nous n'obtenons toujours pas la courbe en cloche, nous avons quand même plus de mesures au centre que sur les côtés. Donc, le nombre de mesures augmente et la fonction de distribution décrite ici par l'histogramme se rapproche d'une distribution normale. Si nous faisons un nombre encore plus élevé de mesures, disons 1000, alors notre histogramme ressemblera vraiment à une distribution normale. Ce n'est pas vraiment simple de faire 1000 mesures, peu importe la mesure dont il s'agit. Heureusement, nous n'avons pas besoin d'autant de mesures pour constater les caractéristiques de la distribution normale. Habituellement, nous n'avons pas besoin d'obtenir cette courbe (gaussienne). Nous avons juste besoin de connaitre les caractéristiques importantes ou les paramètres importants. Ces derniers sont au nombre de deux. La valeur moyenne qui caractérise la position de cette courbe, et l'écart type, S ,qui caractérise sa largeur ou la dispersion des résultats. Plus l'écart type est petit, moins la dispersion est grande. Grâce à l'étude de cette courbe, nous pouvons effectuer des remarques très importantes à propos de sa nature. Si nous nous éloignons de la valeur moyenne d'une unité d'écart type, de part et d'autre, alors nous avons le contour d'une partie de la courbe. Et il s'avère qu'avec les propriétés de la distribution normale, le ratio de l'aire de cette forme par rapport à l'aire totale sous la courbe est d'environ 68 %. Ceci est la base de la défintion de l'incertitude type (u). Cette dernière, comme nous l'avons vu dans plusieurs cas dans d'autres cours, est l'incertitude donnée pour une unité d'écart type et est d'environ 68%. Nous pouvons multiplier l'écart type par des facteurs et si nous le mutliplions par deux alors nous obtenons ce type de courbe. Et maintenant, le ratio de l'aire de cette courbe par rapport à l'aire totale sous la courbe de distribution normale correspond à environ 95,5%. Et cela forme la base de ce que l'on appelle l'incertitude élargie (U). Cette dernière, comme indiqué dans d'autres cours, est obtenue en multipliant l'incertitude type avec avec des facteurs d'élargissement (k). Deux dans ce cas. Et cela nous permet d'obtenir l'incertitude de mesure obtenue avec le plus de probabilité. Ce niveau "2s" ou plutôt incertitude élargie à un niveau de facteur 2, est l'incertitude à environ 95,5% de probabilité. Donc, la probabilité que la valeur vraie tombe dans cet intervalle, est significativement élevée. Pareillement, si l'on multiplie S par 3, alors ce pourcentage sera de 99,7%. |
Toutes les quantités mesurées (mesurandes) sont du point de vue des statistiques mathématiques des quantités aléatoires. Les quantités aléatoires peuvent avoir différentes valeurs. Cela a été démontré dans la vidéo sur l'exemple du pipettage. Si le pipettage avec une même pipette de volume nominal 10 ml est répété plusieurs fois, tous les volumes de pipettage tournent autour de 10 ml, mais restent légèrement différents. Si un nombre suffisamment grand de mesures répétées est effectué et si les volumes [1] pipettés sont tracés en fonction de leur fréquence d'utilisation, il devient évident que bien que aléatoires, les valeurs restent régies par une relation sous-jacente entre le volume et la fréquence : la probabilité maximale d'un volume est comprise entre 10,005 et 10,007 ml et sa probabilité décroît progressivement vers des volumes de plus en plus grands. Cette relation s'appelle une fonction de distribution.
Les mathématiciens connaissent de nombreuses fonctions de distribution et la plupart d’entre elles se rencontrent dans la nature, c’est-à-dire qu’elles décrivent certains processus de la nature. En science de la mesure, la fonction de distribution la plus importante est la distribution normale (également appelée distribution gaussienne). Son importance découle du soi-disant théorème de la limite centrale. De manière simplifiée, les mesures peuvent être libellées comme suit : si un résultat de mesure est simultanément influencé par de nombreuses sources d’incertitude, si le nombre des sources d’incertitude approche de l’infini, la fonction de distribution du résultat de mesure se rapproche de la distribution normale, quel que soit le résultat et les fonctions de distribution des facteurs / paramètres décrivant les sources d'incertitude. En réalité, la fonction de distribution du résultat devient déjà impossible à distinguer de la distribution normale s'il existe 3 à 5 sources (en fonction de la situation) contribuant de manière significative à l'incertitude [2]. Cela explique pourquoi, dans de nombreux cas, les quantités mesurées ont une distribution normale et pourquoi l'essentiel de la base mathématique de la science de la mesure et de l'estimation de l'incertitude de mesure est basée sur la distribution normale.
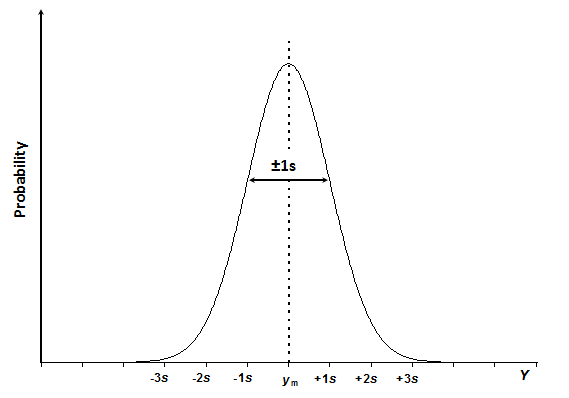
Schéma 3.1. La courbe de distribution normale de la quantité Y avec la valeur moyenne ym et l'écart type s.
La courbe de distribution normale a l'aspect d'une cloche (schéma 3.1) et est exprimée par l'équation 3.1:
 (3.1)
(3.1)
Dans cette équation, f( y ) est la probabilité que le mesurande Y ait la valeur y. ym est la valeur moyenne de la population et s, l'écart type de la population. ym caractérise la position de la distribution normale sur l'axe des ordonnées, s caractérise la largeur (étendue) de la fonction de distribution, qui est déterminée par la dispersion des points de données. La moyenne et l'écart type sont les deux paramètres qui déterminent entièrement la forme de la courbe de distribution normale d'une quantité aléatoire donnée. Les constantes 2 et pi sont des facteurs de normalisation, qui sont présents afin de rendre l’aire totale sous la courbe égale à 1.
Le mot «population» signifie ici que nous aurions besoin de réaliser un nombre infini de mesures afin d’obtenir les vraies valeurs ym et s. En réalité, nous travaillons toujours avec un nombre limité de mesures, de sorte que la valeur moyenne et l'écart type que nous avons dans nos expériences sont en fait des estimations de la moyenne vraie et de l'écart type réel. Plus le nombre de mesures répétées est grand, plus les estimations sont fiables. Le nombre de mesures parallèles est donc très important et nous y reviendrons dans différentes parties de ce cours.
La distribution normale et l'écart type constituent la base de la définition de l'incertitude type. L'incertitude type, appelée u, est l'incertitude exprimée au niveau de l'écart type, c'est-à-dire une incertitude avec une probabilité de couverture d'environ 68,3% (c'est-à-dire que la probabilité que la valeur vraie se situe dans la plage d'incertitude est d'environ 68,3%). La probabilité de 68,3% est souvent trop faible pour des applications pratiques. Par conséquent, l’incertitude des résultats de mesure n’est dans la plupart des cas pas rapportée en tant qu’incertitude type, mais en tant qu’incertitude élargie. L'incertitude élargie, notée U, est obtenue en multipliant l'incertitude type par un facteur d'élargissement [3], noté k, qui est un nombre positif supérieur à 1. Si le facteur d'élargissement est par exemple égal à 2 (qui est la valeur la plus utilisée pour le facteur d'élargissement), dans le cas d'un résultat de mesure normalement distribué, la probabilité de couverture est d'environ 95,5%. Ces probabilités peuvent être considérées comme des fractions d'aire des segments respectifs de l'aire totale sous la courbe, comme illustré par le schéma suivant.
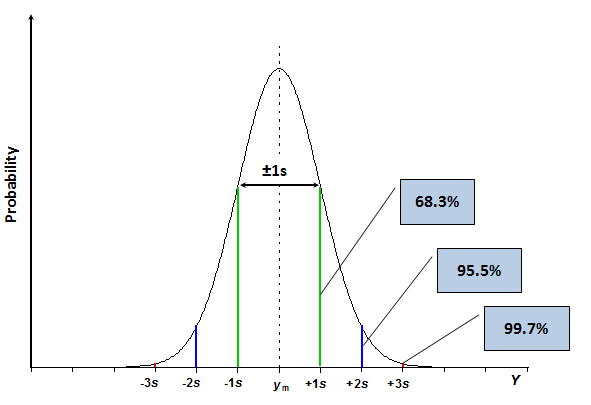
Schéma 3.2. La même courbe de distribution normale que dans le schéma 3.1 avec les segments 2 et 3 indiqués.
Puisque la fonction exposant ne peut jamais renvoyer la valeur zéro, la valeur de f( y ) dans l'équation 3.1 est supérieure à zéro quelle que soit la valeur de y. C’est la raison pour laquelle l’incertitude avec une couverture de 100% n’est (presque) jamais possible.
Il est important de souligner que ces pourcentages ne sont valables que si le résultat de la mesure est normalement distribué. Comme dit plus haut, c'est très souvent le cas. Il existe cependant des cas importants où le résultat de la mesure n'est pas normalement distribué. Dans la plupart des cas, la fonction de distribution a des «queues plus lourdes», ce qui signifie que l’incertitude accrue, par exemple le niveau k = 2, ne correspondra pas à une probabilité de couverture de 95,5%, mais à une probabilité inférieure (par exemple 92%). La question de la distribution du résultat de la mesure dans ce cas sera abordée plus tard dans ce cours.
Autoévaluation sur cette partie du cours : Test 3.1
https://sisu.ut.ee/measurement/node/1396
***
[1] Il est légitime de se demander : comment pouvons nous connaître les volumes prélevés individuellement si la pipette nous “dit” seulement que le volume est de 10mL ? En fait, nous avons seulement la pipette (plus juste) et aucune autre possibilité de mesure du volume, donc on ne peut pas savoir de combien les volumes diffèrent les uns des autres ou par rapport à la valeur nominale. Cependant, si une méthode plus exacte est disponible, alors cela devient possible. Dans le cas du pipettage, une méthode très adaptée et très utilisée est la pesée. Il est possible de trouver le volume d’eau pipetté, qui est plus juste que le volume obtenu juste en pipettant, en pesant la solution prélevée (le plus souvent l’eau) et en divisant la masse obtenue par la densité de l’eau à la température de celle-ci. L’eau est utilisée dans de telles expériences car les densités de l’eau à différentes température sont bien connues (voir : https://en.wikipedia.org/wiki/Properties_of_water#Density_of_water_and_ice).
[2] Les sources d’incertitude dont la contribution est significative sont celles qui sont importantes. Nous avons déjà vu de manière qualitative dans la section 2 que les différentes sources d’incertitude n’ont pas la même importance. Dans les cours à suivre nous verrons également comment “l’importance” d’une source d’incertitude (sa contribution à l’incertitude) peut être exprimée de manière quantitative.
[3] Cette définition de l’incertitude élargie est simplifiée. Une définition plus rigoureuse existe via l’incertitude-type composée sera introduite en section 4.4.